Method
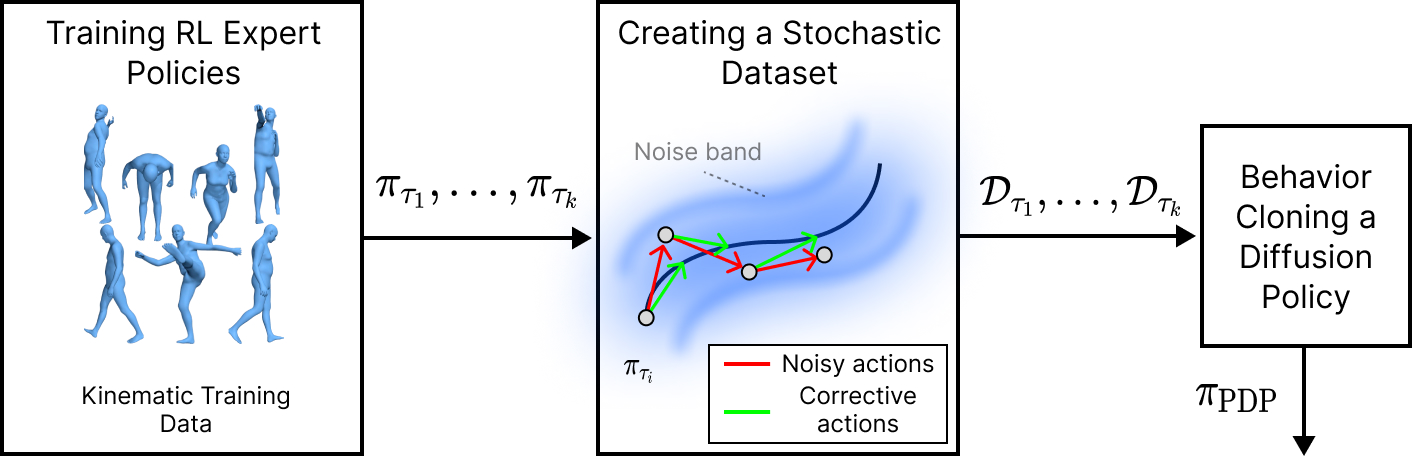
Our method consists of three steps. First, we divide a motion dataset into tasks and train an RL policy for each task. Next, we use the expert policies to collect "noisy-state clean-action" trajectories, where the noisy state is obtained by executing actions from the RL policy with added noise, and the clean action is simply the action from the RL policy without noise. The clean action can be thought of as a corrective action from a noisy state. Lastly, we use the resulting dataset to train a diffusion policy using supervised learning.